
Constructions
The three abstract strata
The DISCOWER corpus includes three text type constructions at various stages of emergence, i.e. from the emerged abstract text, through the basic abstract, to the emerging elaborated abstract. In consonance with Langacker’s (2015) tripartite division, the three abstract layers follow baseline/elaboration [B/E] organization (see Foundations for details), i.e. the abstract text constitutes the initial baseline augmented into the basic abstract augmented into the elaborated abstract:
[B: abstract text] >
[[B: abstract text]E]B: basic abstract >
[[[B: abstract text]E]B: basic abstract E]B: elaborated abstract > … (adapted from Langacker 2015: 2).
Canonically, B/E organization involves adding content to the baseline in an asymmetrical way, as in the case of the nominal construction, where the head noun is augmented by its modifiers (but not the other way round). Analogically, the elaborated abstract can be conceptualized as adding content to, or supplementing, its “head”, i.e. the basic abstract.
While B/E organization typically involves an asymmetry between augmented and augmenting structures, in less typical cases a dual baseline is formed (Langacker 2016: 12), i.e. the two structures elaborate each other, as in the appositive construction, where both structures “have equal claim to the status of […] nominal head” (Langacker 1991: 149). Analogically, the basic abstract can be seen as comprising two “heads”: a (classifying) abstract label (van Langendonck 2007) and a (classified) abstract text (i.e. an encapsulation of a research article).
Another departure from canonical B/E organization involves adding no content to the baseline, i.e. baseline and elaborated structures are the same, as in the case of the zero plural noun construction. Analogically, the abstract text elaborated into, i.e. conceptualized as, the basic abstract but remaining the abstract text in form or the basic abstract elaborated into, i.e. conceptualized as, the elaborated abstract but remaining the basic abstract in form can be viewed as involving an unsymbolized conceptual elaboration (Langacker 2016: 28).
Table 1 below summarizes B/E organization of the three abstract strata.
| abstract stratum | B/E organization | description | minimum B/E organization |
| abstract text | [B] | encapsulation of a research article | B (abstract text) |
| basic abstract | [[B]/B] | classified encapsulation of a research article | B (abstract text) |
| elaborated abstract | [[[B]/B]/E] | supplemented classified encapsulation of a research article | B (abstract text) |
Table 1. B/E organization of the three abstract strata
In consonance with the aims of this project (see Overview), of the three abstract strata in the DISCOWER corpus, two - the basic abstract and the elaborated abstract - are highlighted, i.e. described as form-meaning pairings in two intertwined modes, or layers: paralinguistic and linguistic.
Paralinguistic constructions
The paralinguistic constructions of basic and elaborated abstracts combine punctuation/typography-based forms with attribute-based meanings, facilitating the evaluation of basic and elaborated abstracts as (non-)distinct, (non-)self-contained, (non-)closed, (non-)synchronous, (non-)continuous, (non-)compact, (non-)homogeneous, and (non-)neutral (see Attributes for details).
Linguistic constructions
The linguistic constructions of basic and elaborated abstracts combine (more or less primitive) text-based forms with their functions, facilitating the evaluation of basic and elaborated abstracts as (non-)simple.
While all text type constructions constituting basic and elaborated abstracts, e.g. abstract label, abstract text, keywords, title, author, are conventionalized, i.e. shared by disciplinary communities through scholarly publications and online platforms (see Foundations for details), they are discussed either in a coarse-grained or a fine-grained manner. The former involves such categories as keywords, title, date, author and location, while the latter divides (some of) them into subcategories, e.g.: name, surname, affiliation (for author); publisher, issue number, pages (for location) (Nasar et al. 2018), often in the label/text, a.k.a. the label/content (Schmid 2000), format.
While our corpus yields data at both levels of granularity, we adopt a (more) coarse-grained approach for elaborated abstracts and a (more) fine-grained perspective in the case of basic abstracts, which allows us to properly reflect their respective positions in the abstract hierarchy. To be more specific, elaborated abstracts are characterized with reference to the eight text types in the first column of Table 2 below, which subsume the fine-grained text types in the second column. Basic abstracts, in turn, typically follow the label/content pattern illustrated in the last column.
| coarse-grained text type | fine-grained text type | illustration |
| abstract | encapsulation of a research article (in various language versions), accompanied by a label |  |
| author | a research article’s author’s name, affiliation, contact details, ORCID link, etc., accompanied by labels |  |
| date | a research article’s date of submission, publication, acceptance, etc., accompanied by labels | 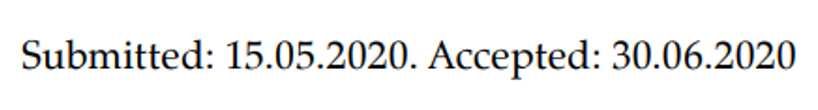 |
| keywords | a set of indicators of a research article’s content (in various language versions), accompanied by a label |  |
| location | a research article’s page (range), issue number, journal (title, address, affiliation, code), etc., accompanied by labels | |
| note | miscellaneous information about a research article, e.g. acknowledgements and copyright, accompanied by labels |  |
| section | a research article’s (peripheral) section, e.g. references and abbreviations |  |
| title | primary and secondary title of a research article (in various language versions) |
|

Table 2. Text types in the DISCOWER corpus
Composition
While paralinguistic and linguistic constructions can be separated for expository reasons, in the DISCOWER corpus they are indeed tightly intertwined into text type-based parts. These parts are distinguished on the basis of semantically-defined coarse-grained text types for elaborated abstracts and (more) fine-grained text types for basic abstracts (see Table 2 above). Thus, a part is internally homogeneous in that it refers to one category, e.g. date, location, recognized either on the basis of its label (e.g. author) or content (e.g. information about the author’s name, affiliation or contact details). Once a new semantic category occurs, e.g. date, a new text type-based part begins. In other words, parts cannot be interrupted by semantically distinct text types; that is, a single text type can potentially occur several times and count as separate parts if there are other text types in between its occurrences. Also, text types in languages other than Polish are counted separately, which is reflected in the way they are recorded, e.g. “keywords” vs “keywords (Polish)”. Finally, since the abstract is our object of study, its label is also described in more detail, i.e. when the PDF file says “abstract”, it is recorded as “abstract (label)”, but when the abstract text is preceded by a label saying “summary”, it is recorded as “abstract (label: summary)”.
The linguistic-paralinguistic interdependence is captured in the DISCOWER corpus by basic and elaborated abstracts’ compositions, i.e. arrangements of their linguistic and (some) paralinguistic constructions (see Attributes for details). While the linguistic constructions in the composition are named according to the conventions detailed above, e.g. a combination of an abstract label and an abstract text will be recorded as “abstract” in the case of elaborated abstracts and “abstract (label)”, “abstract (content)” in the case of basic abstracts, the two paralinguistic constructions detailed in the composition, i.e. synchrony and compactness, are symbolized in the way presented in Table 3 below.
| symbol | meaning |
| | | no extra white space or paralinguistic objects at borders between vertically arranged text type-based parts |
| || | extra white space between vertically arranged text type-based parts |
| { | a paralinguistic object at borders between vertically arranged text type-based parts |
| {{ | extra white space and a paralinguistic object at borders between vertically arranged text type-based parts |
| - - | extra white space at borders between horizontally arranged text type-based parts |
| ~ | a paralinguistic object at borders between horizontally arranged text type-based parts |
Table 3. Conventions for paralinguistic constructions in the DISCOWER corpus
Presented below are exemplars of text type-based parts in basic and elaborated abstracts accompanied by their compositions. While the arrangement of illustrations - from the “biggest” to the “smallest” - generally reflects abstracts’ typicality (see Table 1 above), it also zooms in on B/E organization. In this way, we are able to present basic abstracts with or without insertions between the two “heads” and elaborated abstracts “modified” on one or more sides.








For more information on constructions please contact A. Strugielska or D. Watkowska (see contact information in the footer).