
Principles
The DISCOWER corpus consists of (examples of) three text type constructions, i.e. the abstract text, the basic abstract, and the elaborated abstract. Since the abstract text constitutes the baseline for the other abstract strata (see Constructions for details), it is given separate treatment here, while the basic abstract and the elaborated abstract are discussed in the Procedure section.
In essence, examples of the abstract text available in DISCOWER were selected in accordance with a set of principles, which were established to ensure that the corpus reliably represents the use of written English as a lingua franca (henceforth ELF) within the academic community and captures the (emerging) conventions among its members (see Figure 1 below).
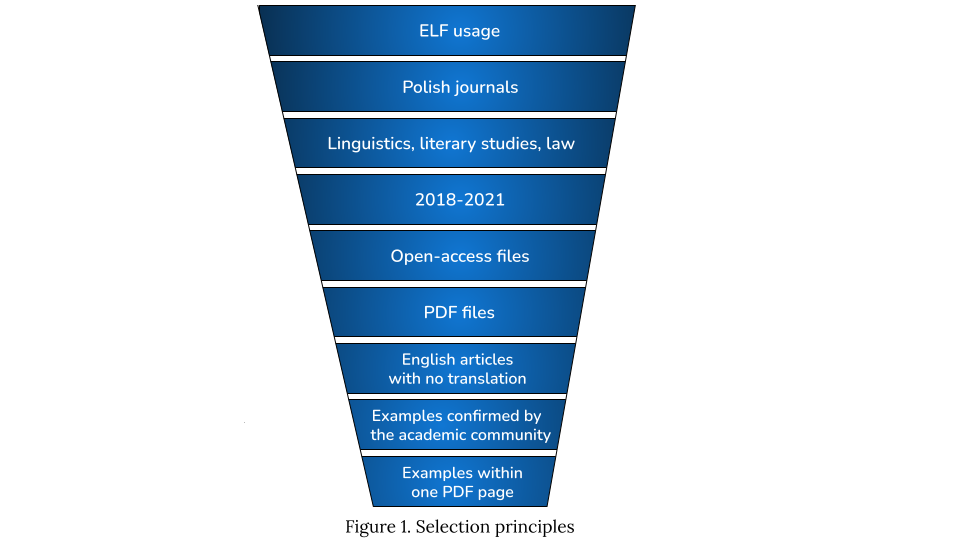
To begin with, in line with the adopted definition of ELF, i.e. the use of English by its native and non-native users for international communication (Seidlhofer 2011), we decided to include examples created by scholars targeting an international readership, irrespective of the scholars’ mother tongue.
For this purpose, we selected Polish journals as our starting point, assuming that the use of English in such journals meets our criteria for ELF usage. In other words, we assume that all individuals involved in creating articles and their abstracts in English and disseminating them through Polish journals (e.g. authors and journal editors) can be considered, by default, ELF users, since they employ their English as a medium for communication with an international, rather than national, audience, adapting it if necessary. We identified Polish journals by checking their International Standard Serial Number at the ISSN Portal for a Polish national code, which a publisher obtains the code from their chosen national ISSN center.
As the only freely available corpus of written academic ELF (i.e. WrELFA) applies a broad binary categorisation of files into the disciplines in “sciences” and “social sciences and humanities”, we chose to complement this categorisation by providing a more fine-grained division within social sciences and humanities, focusing on three disciplines: law, linguistics and literary studies, correlating with the areas of expertise of the DISCOWER team.
To ensure that our choices were not arbitrary, we relied on the lists of journals created by the Ministry of Science and Higher Education in Poland (link 1, link 2), which assign each journal to a specific discipline (or disciplines). Since multidisciplinary journals often lacked clearly defined boundaries between the disciplines involved, we restricted our choices to Polish journals assigned exclusively to a single discipline, thereby avoiding potential ambiguity in the dataset.
At the same time, our reliance on ministerial documents and institutional guidelines influenced our timeframe. More specifically, we chose to collect examples published from 2018, when Poland implemented a new disciplinary classification, up to 2021, when our project officially started.
In addition, we decided to restrict our dataset to examples published in open-access files. This decision not only reduced the need for additional permissions, as we assumed that all individuals had already provided consent for the use of their work, but also enhanced transparency of our dataset, enabling other researchers to consult or build upon the sources included.
Next, we chose to limit our dataset to examples published in PDF files. In fact, due to our interest in analyzing both linguistic (see Constructions) and paralinguistic layers (see Attributes), such an approach helped us minimize the risk of inconsistencies in data description. To clarify, unlike websites, which were frequently updated, reformatted, and relocated, PDF files provided more stable representations of examples, preserving information about their original content and layout.
Additionally, we drew our dataset from articles written in English, without any indication of translation or professional language editing. We assumed that this criterion maximizes the likelihood that each article and its abstract text were written independently by an academic ELF user (i.e. they were not translated or written by another person; for example, we rejected an article marked as a translation at the end).
We further restricted our dataset to examples explicitly described as the exemplars of the abstract text by the academic community, basing this selection on scholarly publications defining types of abstract texts (e.g. informative/indicative) and their purpose, conventional order(s) of abstract components (e.g. Introduction-Methods-Results-Discussion) and the usual context in which abstract texts can be found (e.g. close to the article’s title and information about the author) (see Inspirations for details). We also read the International Standard for abstracts for publications and documentation, which helped us distinguish between abstract texts (used for primary publications, such as journals) and combinations of abstract texts and, e.g., titles and information about the author (used for secondary publications) (see our distinction into abstract texts and basic abstracts illustrated in Procedure). Moreover, we consulted websites through which our abstract texts could be accessed and noticed that “abstract” and “summary” interchangeably preceded abstract texts.
{kind=link}
Still, since we did not want to prematurely limit the number of examples in the corpus, this knowledge constituted only general guidelines. Hence, in practice, when a short text encapsulating the content of a research article (but not constituting its part) appeared in the PDF file in the vicinity of, e.g., the article (usually above), the article’s title (usually below), keywords (usually above) or the abstract label (usually below or to the right), we accepted it as an exemplar of the abstract text. In fact, labelled examples, i.e. abstract texts preceded by “abstract” or “summary”, were relatively unproblematic to categorize as abstracts, while in labelless cases we consulted journal websites (identified by Arianta 2 journal information portal, recommended for Polish academic open access publishers) to see if our candidates were identified as abstracts there. Thus, for instance, an abstract text with no label in the PDF could be identified based on the website label. In such cases where the identification failed (e.g. the website label for a labelless PDF text was absent or pointed to a different text type, such as a part of the article, a title or a quotation), the candidate was not included in the corpus.
Lastly, only examples fully contained within a single PDF page were collected to limit the amount of data we were able to handle at this stage of the project (see Attributes and Procedure for details). See an example of an abstract text split across two pages and thus rejected from the corpus.
For further details on Principles, please contact D. Watkowska and D. Guttfeld (contact data below).