
Procedure
The DISCOWER corpus comprises (examples of) three varyingly conventionalized abstract strata, i.e. the abstract text, the basic abstract, and the elaborated abstract (see Constructions for details). As the abstract text functions solely as the base from which more complex abstract strata are derived (i.e. it is not yet descirbed through attributes), the criteria for its selection are presented separately (see Principles for details). In this section, we describe the two-stage identification procedure of (examples of) the basic abstract and the elaborated abstract, which constitute the focus of our project.
STAGE 1: The basic abstract
Given its higher degree of conventionalization, i.e. wider recognition within the academic community (see e.g. journal and publisher editiorial guidelines), the basic abstract’s boundaries are determined based on its typical linguistic constituents. More specifically, the identification of the basic abstract typically involves recognizing its two component text type constructions, i.e. the abstract label (“abstract” or “summary”) and the abstract text.
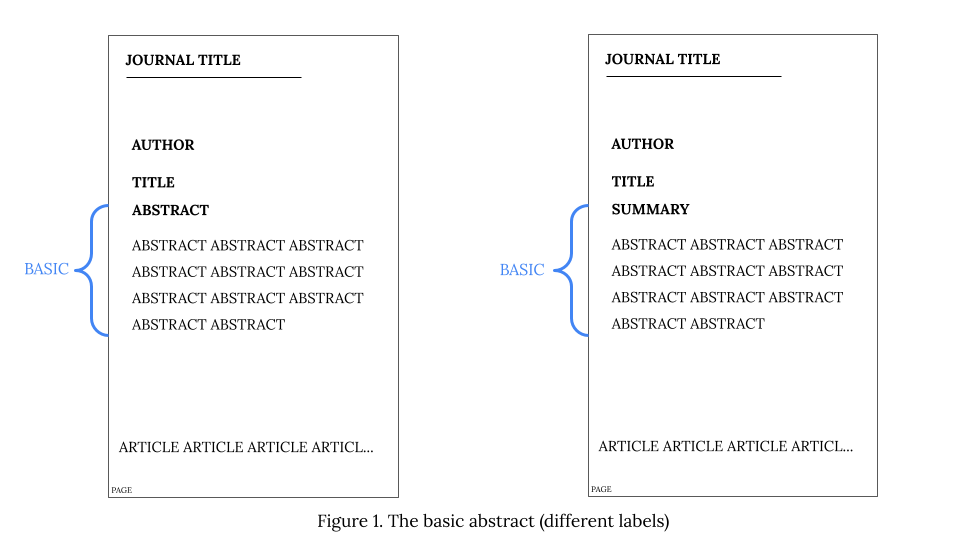
When additional text type constructions (such as titles) occur between a given abstract label/text pairing, they are also accepted as text type-based parts of the basic abstract which is then viewed analogically to an appositive construction with insertions (see Constructions for details).
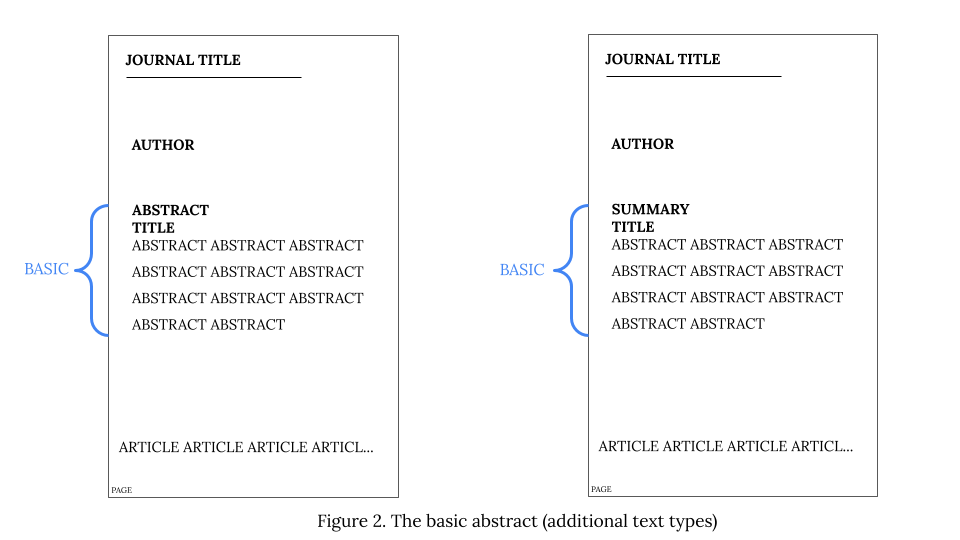
In cases where no label is provided, every abstract text is also considered the basic abstract albeit in the minimum version.
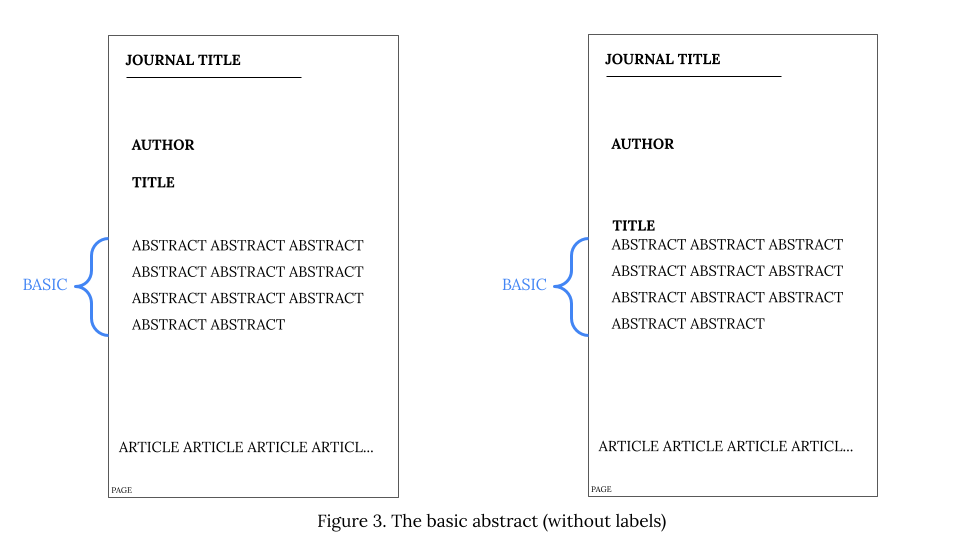
Since the abstract text is always a part of the basic abstract, and hence a convenient starting point for its recognition, Stage 1 of our identification procedure can be depicted in the way provided in Graph 1 below.
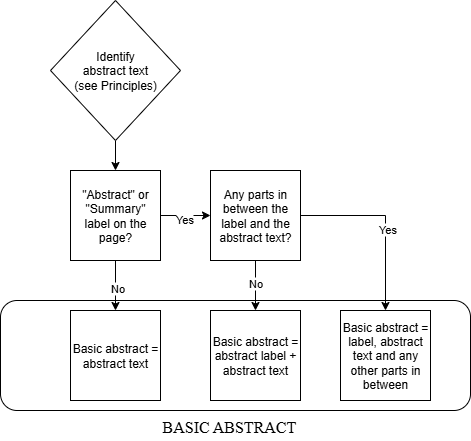
Graph 1. Identifying the basic abstract.
STAGE 2: The elaborated abstract
Due to its lower degree of conventionalization, the elaborated abstract cannot be recognized through its initial and final linguistic constructions. Thus, the identification procedure involves a paralinguistic delineation of groupings, roughly equivalent to establishing mutual clusters, in which “relationships are defined by each object’s relative proximity to the next” (Fletcher 2021: 33).
Preferred over other grouping factors due to its consistent presence in our data, proximity entails that “[e]very visual item within the layout has a margin [i.e. white space] around it that determines its specific relationship to the next object. Objects that have smaller margins—than other margins on the layout—between them will be read as pairs or sets of objects and therefore will be understood together as a conceptual unit” (Fletcher 2021: 33).
Such proximity-based units would be analogical to chunks (see Vetchinnikova et al. 2022) in the visual mode. However, applied to our objects, i.e. text type-based parts (see Constructions for details), the assessment of distance has to involve several specific assumptions to ensure grouping consistency and replicability (in keeping with postulates voiced by Mason 2008 and Habjan 2013).
First of all, we analyze only the size of full-length white space which vertically separates (typically black) parts as a single-column, top-to-bottom arrangement dominates in the PDF files taken into consideration (see Principles for details).

Secondly, we limit our identification procedure to a single page of each PDF file to be able to analyze every journal in the same way, i.e. by viewing each page in a full-screen, single-page format and analyzing distance between parts without crossing page boundaries. All text-type based parts (henceforth: parts) extending beyond the boundaries of a single PDF page (e.g. an article’s first paragraph positioned at the bottom of a page and continued on the following page, crossed-out in Figure 5 below) are valid for assessing distance but not for inclusion within the elaborated abstract (see Attributes for details).

Finally, we always determine the largest grouping possible around the basic abstract, i.e. the largest grouping whose internal distances between and within parts are smaller than external distances to other parts, so as to fully explore the potential scope of elaboration. Essentially, identifying such a grouping involves measuring the distances within the basic abstract (whether equal to the abstract text, containing the abstract label/text pairing, or containing more constituents as well) and comparing them to those outside, i.e. to distances to and within other parts.
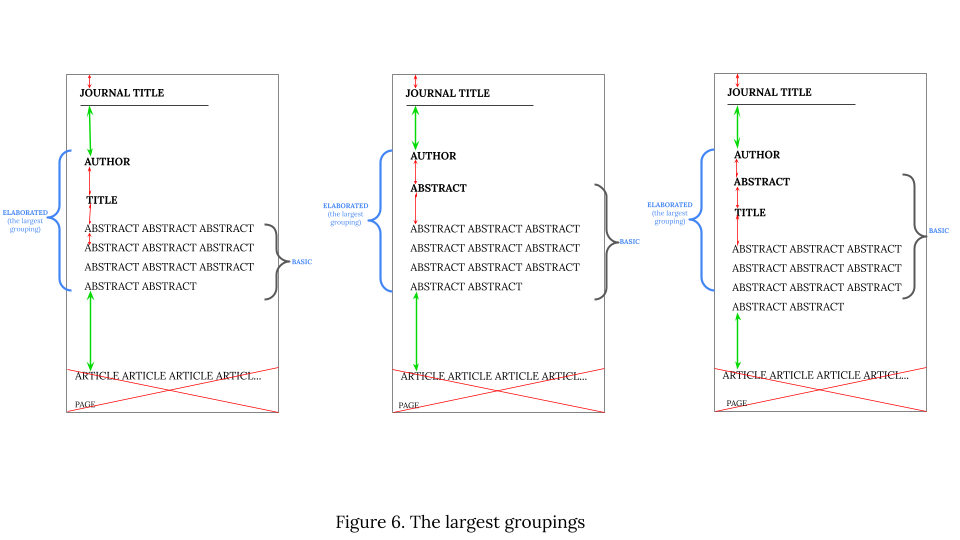
Figure 6 shows three examples of the basic abstract representing three levels of complexity as points of departure for delineating elaborated abstracts. In each case, we evaluate potential groupings by comparing the largest distance within the grouping being tested to this grouping's external distances (above and below).
In Figure 6 on the left, we evaluate the potential grouping of the basic abstract (comprising only the abstract text) with the title by comparing the largest distance within the basic abstract text (i.e. the interline spacing) to the internal distance between the abstract text and “title”, and the external distances: between the title and the author (above the grouping) and between the abstract text and the article (below the grouping). The external distances are larger than the internal distances, which makes the grouping valid. However, this grouping is not the largest on the page. Thus, we evaluate other groupings. The grouping of the basic abstract + the title + the author is also valid, as the distances above the author and the distance below abstract text (see green arrows) are larger than the largest distance within the grouping (red arrows). As the largest valid grouping on the page, this is accepted as the elaborated abstract.
In Figure 6 in the middle, the basic abstract comprises the abstract label and the abstract text. For the purposes of evaluating the basic abstract's grouping with the author, the largest internal distance in the basic abstract, that is the distance between the abstract label and the abstract text, is compared to the internal distance from the abstract label to the author, and to external distances: from the author to the location (journal title above the grouping) and between the abstract text and the article (below the grouping). As the external distances (green arrows) are larger than the internal ones (red arrows), the author can be grouped with the basic abstract. Since this is also the largest valid grouping on the page, it constitutes the elaborated abstract.
By the same token, in the third case on the right, where the basic abstract also includes the title situated between the abstract label and the abstract text, the largest internal distance in the basic abstract (i.e. the distance between the title and the abstract text) is compared to the internal distances (between the the abstract label and the author) and to the external distances: between the author and the location (above the grouping), and between the abstract text and the article (below the grouping). As the external distances (green arrows) prove larger than internal distances (red arrows) and this is the largest valid grouping on the page, it constitutes the elaborated abstract.
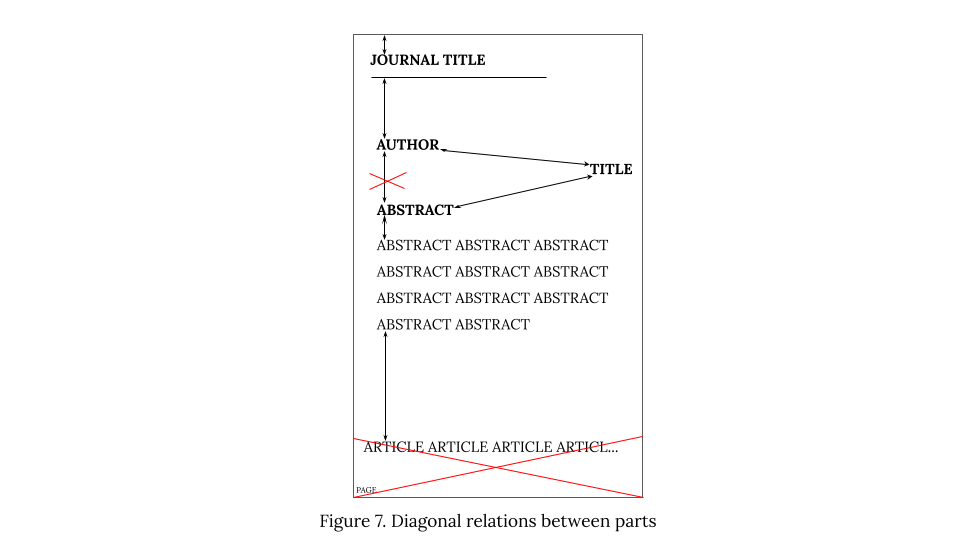
In cases where text-type based parts are not arranged vertically (i.e. it is not possible to assess distances separating parts along the vertical axis alone), the following rules are applied:
-
If some parts are arranged diagonally (see the abstract and the title below), the shortest distance between them is evaluated. In other words, parts positioned diagonally cannot be omitted while evaluating distances, even if the distance to others directly above/below is shorter (see the author and the abstract below).
- If parts are arranged symmetrically in a multi column, left-to-right arrangement (i.e. they start and end at the same vertical level, see the abstract and streszczenie below), they are treated interchangeably when measuring distances to text type-based above or below them (see, e.g. the keywords below). In this situation, always the shortest distance is taken into consideration (see the distance between the abstract and the keywords rather than streszczenie and the keywords).

If such parts are not exactly symmetrical (see, e.g., “abstract” and “streszczenie”), distances are measured from the first or last line of the object that extends higher or lower (e.g. “streszczenie”) to the object above or below (e.g. “keywords”).

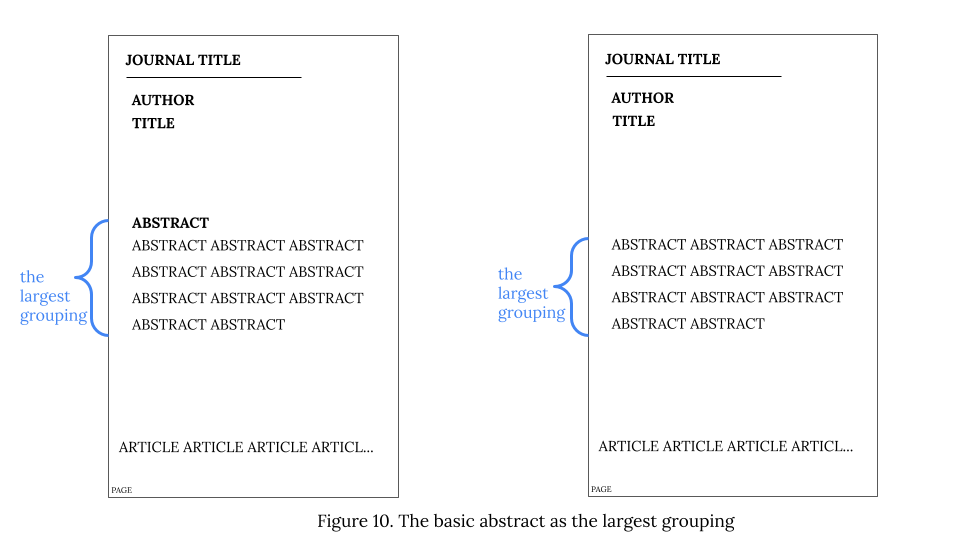
In cases where parts are arranged in such a way that it is not possible to establish a grouping larger than the basic abstract, the basic abstract (of varying complexity) is considered the largest grouping possible (see Figure 10 below).
Thus, like the basic abstract, the elaborated abstract may have either minimally or maximally elaborated versions (see Graph 2 below).
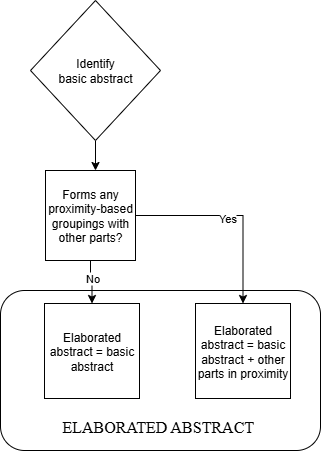
Graph 2. Delineating the elaborated abstract.
Once the identification procedure is completed, the basic abstract and the elaborated abstract are ready to be described in terms of their linguistic (see Constructions for details) and paralinguistic layers (see Attributes for details).
For further details on Procedure, please contact D. Watkowska and D. Guttfeld (contact data below).